
Table of Contents
- Background
- When to run a clustering algorithm on dimensionality reduction (e.g. viSNE/opt-SNE/tSNE-CUDA/UMAP) channels
- When to display clusters (e.g. from FlowSOM/SPADE/CITRUS) on dimensionality reduction maps
- Directions for running a clustering algorithm on dimensionality reduction algorithm data in Cytobank
- Analysis of the results of running a clustering algorithm on dimensionality reduction algorithm data in Cytobank
Background
Dimensionality reduction (DR) techniques are excellent methods for condensing high-dimensional data to two-dimension and thereby enabling rapid exploratory data analysis and visualization of complex results. For cytometry data, this may assist with the categorization of events/cells into biological populations. For bulk data, this may help you understand the heterogeneity in your samples. In either case, it is sometimes useful to categorize groups seen on DR maps for downstream analysis. This can be done using gates:
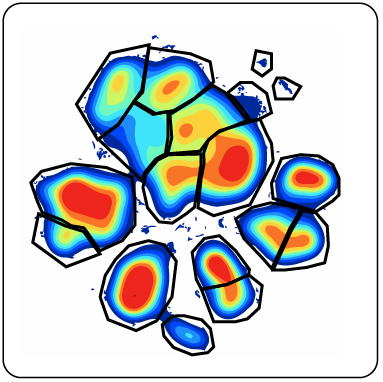
(Areas of a viSNE map categorized into populations using gates)
To learn more about this process, read our article about gating a dimensionality reduction map. Creating, gates for DR maps can be time-consuming, subjective, and detail-driven process. An alternative is to use a computer-driven clustering method to categorize groups seen in DR maps automatically. There are multiple approaches that can be used for clustering a dimensionality reduction map, one of which is running FlowSOM, SPADE, or CITRUS on the coordinates of the DR maps themselves. The result of running FlowSOM, SPADE, or CITRUS on DR maps is a collection of clusters that correspond to spatial locations on the map. Another approach that leverages the display of clustering data on DR maps is to run SPADE, FlowSOM, or CITRUS on the population-defining markers (e.g. CD markers) and to display the resulting clustering data overlaid on the DR map. Finally, DR maps facilitate clustering quality assessment, help compare different algorithm run settings and provide a good starting point for analysis of clustering data.
When to run a clustering algorithm on dimensionality reduction channels
Clustering on DR channels (e.g. viSNE/opt-SNE/tSNE-CUDA/UMAP channels) can be a useful approach for defining groups of cells or groups of samples when the dimensionality of your data is very high. In these cases, the "curse of dimensionality" may cause a clustering method to be unable to perform well unless you first reduce the dimensionality of the data. Unfortunately, because every dataset is different, it's hard to know when you may reach this point. If your data are very high-dimensional cytometry data, data with hundreds of markers measured in all your samples, or you are noticing that your clustering results don't make sense, clustering on DR (e.g., viSNE/opt-SNE/tSNE-CUDA/UMAP) channels may be a better option for defining groups of cells or groups of samples.
When to display clusters (e.g. from FlowSOM/SPADE/CITRUS) on dimensionality reduction maps
If clustering on DR channels isn’t appropriate for your workflow, you may still benefit from combining clustering and dimensionality reduced data alongside your native data to allow you to display clustering data on a DR map. This can help with clustering algorithm optimization and with the assessment of cluster identity. In this workflow, you cluster on the typical population-defining channels (e.g., CD markers), gate the clusters, and overlay the gated cluster Populations on the DR map. You can run the DR algorithm either before or after running the clustering algorithm.
Directions for running a clustering algorithm on dimensionality reduction experiment
1) Navigate to the dimensionality reduction analysis
In order to run a clustering algorithm on DR analysis results, first, navigate to a DR analysis experiment (see How to configure and run a dimensionality reduction analysis)
2) Choose a clustering method
Within the DR analysis experiment that houses the DR algorithm result files, choose a clustering algorithm to configure within the Advanced analyses menu. From within the Advanced analyses menu, you can choose to create a New analysis for either clustering algorithms (SPADE or FlowSOM) as well as initiate a new Citrus algorithm analysis.
The following articles provide detailed information on how to configure a clustering analysis:
- How to Configure and Run a FlowSOM Analysis
- How to Configure and Run a SPADE Analysis
- How to Configure and Run a CITRUS Analysis
Here are some guidelines that apply specifically to this workflow of clustering on DR algorithm channels:
Population
The files being included for this clustering analysis are the results from your previous DR algorithm analysis. Thus, the Ungated population corresponds to the population that was previously chosen for DR algorithm run. For that reason, simply choose ungated for the clustering analysis. A more restrictive population can be chosen if desired for some other workflow objective.
Clustering channels
For the workflow of clustering on the DR algorithm channels to overcome the “curse of dimensionality”:
Choose only the two DR annotation channels for example tSNE1 and tSNE2. This application is for clustering the map only and thus other channels should not be included on the clustering step.
For the workflow of displaying clustering data on a DR algorithm map via a standard clustering approach:
Choose only the population-defining markers (e.g., CD markers). The other markers will carry through to the analysis even if they aren’t selected as Clustering Channels.
Fold-Change Groups (applicable to SPADE only)
The typical logic applies for choosing fold change groups and baselines with SPADE. This is a useful way of getting fold change visualizations for a DR algorithm map, which is usually not possible due to the single-cell nature of DR algorithm results.
Number of Clusters (Nodes)
The number of clusters may need to be honed empirically, but a good starting place may be ~7 times the number of populations you expect to find based on manual gating. On some of the publicly available datasets published in Weber & Robinson (2016), we demonstrated that starting with a number of clusters equal to ~7 times the number of expected populations based on manual gating, we were able to capture all of the populations with a frequency > 0.5% with an F measure that was comparable to the other clustering methods used in that paper.
Analysis of the results of running a clustering algorithm on dimensionality reduction algorithm data in the Cytobank platform
One approach to analyzing the results of clustering on DR channels is to proceed with a typical analysis workflow. For SPADE, this means the typical analysis of a normal SPADE run, including coloring by channel, bubbling, fold change analysis, statistics, exporting FCS files based on bubbles, etc. The way in which the SPADE tree was created is different, but the analysis follows the same principles. The same is true for FlowSOM and CITRUS output.
Regardless of whether you chose to cluster on the DR algorithm channels or on the population-defining markers, it can also be informative to visualize the clusters overlaid on a DR map. This approach can help you gauge the quality of the clustering and can aid in the refinement of clustering algorithm settings. Generally, the colors of the overlaid clusters should correspond to the DR algorithm continent definitions. If the same cluster spans multiple continents, that might indicate a need to increase the target number of clusters (or clusters and metaclusters, in the case of overlaying FlowSOM metal clusters on a DR map), or a need to enable or disable normalization. You can also use the Automatic cluster gates functionality to create Populations out of clusters or metal clusters or to refine the results of FlowSOM-driven meta clustering.

You can compare overlaid clusters on a DR map to a contour plot of the DR map to gauge whether the number of clusters generated was sufficient to capture distinct, dense populations. In the example above, you can see how a FlowSOM target number of metal clusters of 4 does not provide enough resolution, and a target of 15 provides too much resolution (though you could further explore this to see if, in fact, it is detecting relevant sub-populations). A target number of metal clusters of 7 appears to yield good correspondence between the FlowSOM meta clustering and the viSNE continents (note that in this dataset, the central, pink continent is identifiable only as being CD16+ based on the staining reagents used in the experiment; hence, the identification of one meta cluster despite the two dense regions visible in the contour plot view). When a FlowSOM run finishes, you land automatically in the Illustration Editor configured with this view of FlowSOM metal clusters on a DR map if your dataset also has the DR annotation channels (e.g., tSNE1 and tSNE2), making it easy to perform this quality assessment rapidly.
This is the same dataset passed through FlowSOM with all settings identical, with the exception of Normalization now being enabled (it was disabled in the prior example):
This is the same dataset passed through FlowSOM with all settings identical, with the exception of Normalization now being enabled (it was disabled in the prior example):
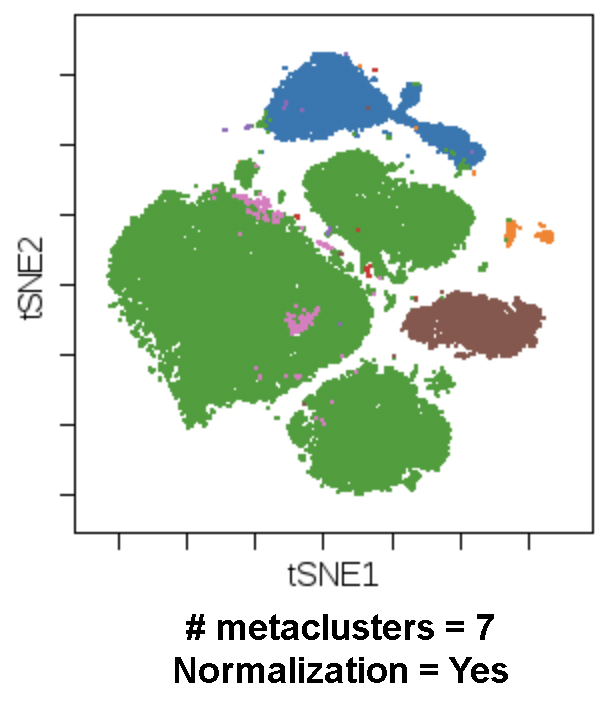
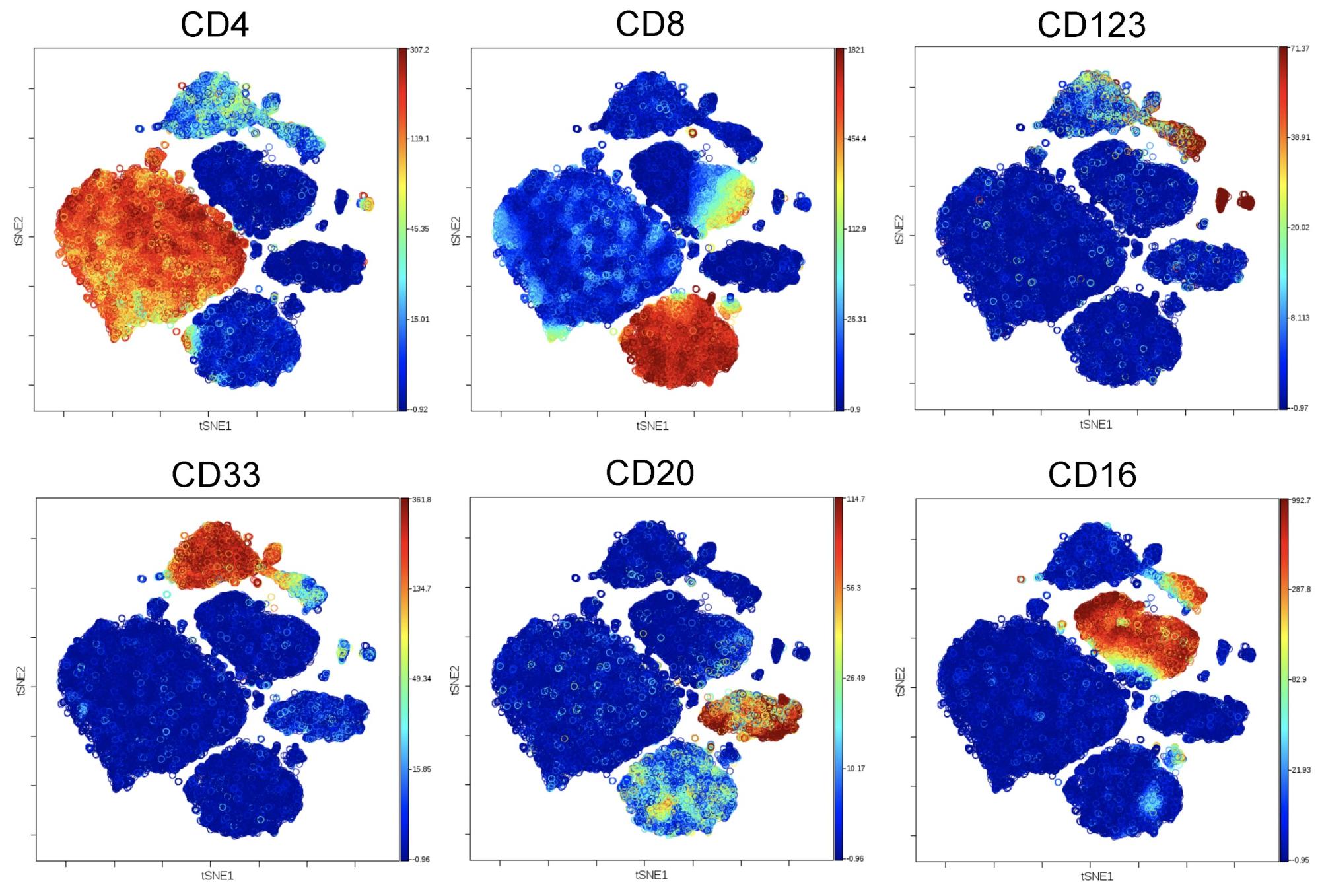
While normalization is often a helpful and necessary approach to transform channel data prior to analysis, for some datasets it is not (see example above), and that can be rapidly detected via the display of FlowSOM metal clusters on a DR algorithm map, followed up by an inspection of cluster expression:
{kind=link}
If you find that enabling normalization appears to diminish the resolution of the meta clustering, you can also try increasing the target number of meta clusters. There may be cases where enabling normalization appears to lower the resolution and results in poor quality, but by increasing the target number of meta clusters, you may be able to pull out sub-populations.
Now that you have optimized your clustering algorithm run, you can now proceed to view the expression of markers of interest in a heatmap format or to drill down into single-cell views.
How to perform the analysis workflow with FlowSOM:
When a FlowSOM run completes, it writes FlowSOM_cluster_id and FlowSOM_metacluster_id channels into the newly generated files that comprise the FlowSOM analysis experiment. If you have followed the steps above and run a DR algorithm on the files first, the files in the FlowSOM analysis experiment will now contain all the original channels and data, as well as the annotation channels from the DR algorithm run (e.g., tSNE1 and tSNE2), and the new FlowSOM_cluster_id and FlowSOM_metacluster_id channels. The illustration will be configured by default to set up dot plots with meta clusters overlaid on the DR algorithm map. (You can also run FlowSOM first, and then run a DR algorithm - the same smart illustration view will be set up following the DR algorithm run.) From here, you can assess meta clusters identity by setting up heatmaps or channel-colored dot plots to view the expression of clusters of interest.
Completing the analysis workflow with SPADE:
First, run the DR algorithm on your dataset. Then run SPADE per the instructions above. Following completion of the SPADE run, start in the SPADE result (tree viewer page) and draw a single bubble around the entire SPADE tree. Next, export the bubble as new FCS files. The resulting files will have a Cluster ID channel that can be used to draw cluster gates, which then will allow the visualization of the DR algorithm map colored by cluster using colored overlay populations, or heatmap display of cluster expression for markers of interest. You’ll set the x- and y-axes to the DR annotation channels (e.g. tSNE1 and tSNE2), select your cluster gates for the Populations, and set the plot type to Dot colored by Overlaid Figure Dimension.
Completing the analysis workflow with CITRUS:
First, run a DR algorithm on your dataset. Then run CITRUS per the instructions above. Following completion of the CITRUS run, export the clusters in which you are interested to a new experiment. Set the x- and y-axes to the DR annotation channels (e.g. tSNE1 and tSNE2), and ensure your files are annotated, leveraging the Figure Dimensions. For example, if you have used the Sample Types figure dimension to annotate your CITRUS cluster files, put the Sample Types Figure Dimension in the second position and set the plot type to Dot colored by Overlaid Figure Dimension.
Have more questions? Submit a request